Das Molekül des Lebens ist die DNA. Das liegt daran, dass DNA Information enthält und kopiert werden kann. Diese Kopien sind jedoch nicht perfekt, sondern enthalten kleine Veränderungen. Manche dieser Veränderungen verbessern die Kopierung der DNA, wodurch diese Veränderungen logischerweise auch öfters kopiert werden. Es findet eine Selektion derjenigen Veränderungen statt, die eine besonders effiziente Kopierung ermöglichen: sie setzen sich gegenüber weniger effizienten Veränderungen durch. Diese natürliche Selektion setzt eine Evolution in Gang, und dadurch auch das Phänomen, welches wir als Leben bezeichnen.
Wie ist DNA aufgebaut?
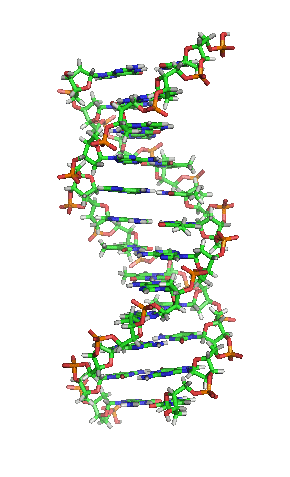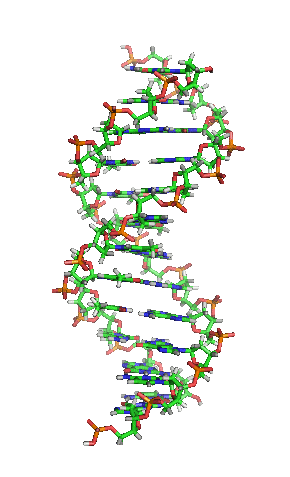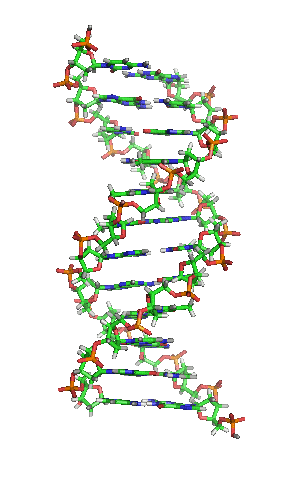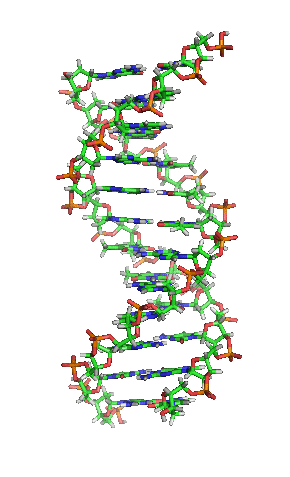
DNA gehört zur Gruppen der Nukleinsäuren. Ausgeschrieben steht DNA für deoxyribonucleic acid. Im Deutschen “Desoxyribonukleinsäure”, mit der entsprechenden Abkürzung DNS, die aber heutzutage nicht mehr verwendet wird. DNA ist ein lineares Polymer aus sogenannten (Desoxy-)Nukleotiden. Diese Nukleotide bestehen aus einer Phosphatgruppe, einem Zucker (bei der DNA die der Desoxyribose) und einer von vier Basen. Die Basen heißen Thymin (T), Cytosin (C), Adenin (A) und Guanin (G). Sie bilden die Buchstaben, mit denen die genetische Information niedergeschrieben ist. Wie schon bei den Proteinen liegt auch dieses Polymer jetzt nicht als einfacher DNA-Faden in der Zelle herum. Im Gegensatz zu den Proteinen gibt es jedoch nur eine Struktur, die von DNA eingenommen wird: die der berühmten Doppelhelix. Dabei winden sich zwei DNA-Fäden umeinander. Der Witz daran ist, dass das nur stattfinden kann, wenn die Basen beider Moleküle zueinander passen (komplementär zueinander sind). Thymin (T) bindet immer an Adenin (A), und Cytosin (C) immer an Guanin (G). Das liegt an ihren Strukturen. Adenin und Guanin sind sog. Purine und etwas größer und brauchen daher als Bindungspartner eine kleinere Base, sog. Pyrimidine. Durch die Doppelhelixstruktur ist aber auch gewährleistet, dass – wenn man beide Stränge voneinander trennt – jeder Strang als Vorlage für einen neuen Strang dient. Denn zu jeder Base passt immer nur eine andere. So kann die DNA einfach und weitgehend fehlerfrei vervielfältigt werden. Die biologischen Eigenschaften der DNA als Erbinformation leiten sich also aus ihrer chemischen Struktur ab.
{kind=link}

Und was ist mit RNA?
Der zweite Vertreter der Nukleinsäuren ist die RNA (engl. ribonucleic acid). Sie ist prinzipiell sehr ähnlich aufgebaut wie DNA, mit zwei kleinen, jedoch bedeutsamen Unterschieden. Zum einen unterscheidet sich der Zuckeranteil, wie der Name DNA / RNA schon verrät: die DNA benutzt als Zucker die Desoxyribose, RNA die Ribose selber. Im Gegensatz zu den Desoxynukleotiden (Bausteine der DNA) sind die Nukleotide also Bausteine der RNA. Zum anderen unterscheiden sich RNA und DNA in den Basen, die sie verwenden: in RNA wird statt Thymin die Base Uracil (U) verwendet.
Im ersten Kapitel haben wir schon das ATP als “Energiewährung” der Zelle kennen gelernt. ATP steht für Adenosin-Triphosphat. Adenosin ist die Bezeichnung für Adenin, das mit einer Ribose verbunden ist (ein Nucleosid), aber noch keine Phosphatgruppe enthält. ATP trägt zusätzlich noch drei Phosphatgruppen. Die sog. Phosphodiesterbindungen zwischen den Phosphatgruppen sind sehr energiereich und in ihnen ist die Energie, die z.B. aus dem Abbau von Glucose gewonnen wird, gespeichert. Enzyme, die energieaufwendige Reaktionen katalysieren, benutzen diese Energie aus dem ATP, indem sie die Phosphodiesterbindungen spalten (“hydrolysieren”, da sie dafür Wasser benötigen) und die entstehende Energie für ihre Reaktion verwenden. In seltenen Fällen wird statt ATP auch GTP verwendet – das Molekül ist das gleiche, nur ist die Base nicht Adenin, sondern Guanin.

Das zentrale Dogma der Molekularbiologie
Welche Rolle spielen nun DNA und RNA in der Zelle? Unter dem zentralen Dogma der Molekularbiologie versteht man den Vorgang, dass Information aus der DNA in RNA umgeschrieben wird, und dann in ein Protein übersetzt wird.
Der Begriff “Dogma” ist denkbar dumm gewählt. Er wurde von den Entdeckern der DNA-Doppelhelix, Francis Crick und James Watson geprägt. Beide hatten allerdings etwas andere Definitionen, was genau gemeint sein soll. Ein Dogma beschreibt jedoch eine unanfechtbare, absolute Wahrheit, die durch keine neue Erkenntnis jemals widerlegt werden kann. So was kennt man aus der Religion, hat aber in der Wissenschaft nichts zu suchen. Wissenschaftler sind immer bereit, alte Ideen und Theorien zu verwerfen, sollte es neue Daten geben die sie unhaltbar machen. Wissenschaft kennt prinzipiell keine Dogmen, und Dogmen sind immer auch schlechte Wissenschaft. Das bedeutet nicht, dass wir “nichts wissen können” oder noch nicht einmal, dass wir uns bei manchen Sachverhalten nicht sicher sind. Im Gegenteil, wir wissen z.B. mit überwältigender Sicherheit, dass das Leben auf der Erde sich im Laufe der Evolution entwickelt hat und nicht erschaffen wurde. Die Wahrscheinlichkeit beträgt 99,9999999% (oder wie viele Nachkommastellen auch immer), aber eben nicht genau 100%, denn prinzipiell könnte es möglich sein, dass wir unsere Meinung doch in Zukunft anpassen müssen. Das wird nicht passieren, aber der Unterschied zum Dogma ist genau diese prinzipielle Bereitschaft, seine Ansicht zu revidieren. Details der Evolutionstheorie werden ohnehin ständig durch neue Forschung revidiert und verfeinert. Zum Beispiel wenn wieder ein neues Fossil gefunden oder eine neue Spezies Mensch entdeckt wird. Auch das zentrale Dogma der Molekularbiologie musste schon revidiert werden: in der ursprünglichen Formulierung sieht es eine Einbahnstraße von DNA -> RNA -> Protein vor. Manche Viren wie z.B. HIV können jedoch ihre Erbinformation, die als RNA vorliegt, in DNA umschreiben (mittels eines Enzyms, das sich reverse Transkriptase nennt).
Das läuft folgendermaßen ab. DNA befindet sich in Form von Chromosomen im Zellkern. Ein Abschnitt DNA, der den Bauplan (d.h. die Aminosäuresequenz) eines Proteins enthält, wird (vereinfacht) als Gen bezeichnet. So ein Gen wird nun abgelesen, indem ein Enzym eine Kopie der DNA-Sequenz generiert – jedoch als RNA. Dieser Prozess wird Transkription genannt. Aus der Sequenz ATGTATC (DNA) wird nun also AUGUAUC (RNA). Diese RNA wird als messenger-RNA (mRNA) bezeichnet, im Deutschen manchmal auch als Boten-RNA übersetzt. Sie wird nun aus dem Zellkern in das Zytosol der Zelle geschleust. Dort finden sich Komplexe aus Proteinen und RNA, die man Ribosomen nennt. Sie binden jetzt an die mRNA und übersetzen ihre Information in ein Protein (Translation genannt). Dabei ist es so, dass immer drei Nukleotide der RNA eine der zwanzig proteinogenen Aminosäuren vorgeben (der sog. genetische Code). UAU kodiert beispielsweise für die Aminosäure Tyrosin. AUG kodiert für die Aminosäure Methionin, und ist gleichzeitig das sog. Startcodon, d.h. das Codon, das dem Ribosom signalisiert, wann es mit der Translation beginnen soll. Dementsprechend gibt es auch Codons, die dem Ribosom signalisieren, dass die Translation hier abgebrochen werden soll, da das Protein zu Ende ist.
Wieso betreibt die Zelle so einen Aufwand? Wäre es nicht einfacher, ein Protein direkt von der DNA abzulesen? Wieso der mRNA-Zwischenschritt? Eine Antwort auf diese Frage ist, dass dadurch deutlich mehr Protein gebildet werden kann. Man muss bedenken, dass es für die allermeisten Proteine nur ein Gen (in zwei Allelen) im Zellkern gibt. Viele Proteine müssen aber Tausend-, Zehntausendfach oder noch öfters produziert werden. Daher baut die Zelle zunächst viele mRNAs, von denen dann jeweils mehrere Proteinkopien abgelesen werden können. Dadurch kann in kürzerer Zeit eine viel größere Menge an Protein generiert werden.

Zurück zu unserem Ausgangsvideo. Wieso ist die Befürchtung, eine RNA-Impfung könnte unser Genom verändern, so abwegig? Nun, durch die Impfung gelangt RNA erstmal nur ins Zytosol der Zelle. Die DNA befindet sich aber wie erwähnt im Zellkern. Es gibt also gar keine Möglichkeit, wie beide miteinander interagieren können. Außerdem gibt es in menschlichen Zellen keine reverse Transkriptase, die RNA in DNA umschreiben könnte. Und RNA selber könnte nie in DNA “eingebaut” werden. Zu guter Letzt wird RNA im Körper – und auch im Zytosol der Zelle – schnell wieder abgebaut. Sonst würde die Zelle ja irgendwann vor lauter mRNA platzen. Nach einiger Zeit findet sich also gar keine “Impf-RNA” mehr in der Zelle. Das dürfte spätestens nach einigen Tagen der Fall sein, denn die Halbwertszeit von mRNA beträgt maximal Stunden, häufig auch nur Minuten. Und selbst wenn das eine begründete Befürchtung wäre (was sie nicht ist!), würde das gleiche Problem natürlich bei einer ganz normalen Infektion mit SARS-CoV-2 (oder jedem anderen RNA-Virus, wie z.B. eines einfachen Rhinovirus auch auftreten, und wäre damit gar kein Argument gegen die Impfung.
Mit ein paar Grundlagen darüber, was DNA überhaupt ist und was sie macht kann man also schon einen der derzeit kursierenden Impfmythen widerlegen. Daher ist es so wichtig, ein wenig biologisches Grundwissen zu besitzen. Denn teilweise sind pseudowissenschaftliche Behauptungen einfach völlig aus der Luft gezogen, motiviert durch persönliche Überzeugungen (und nicht auf der Datenlage aufbauend), und unglaublich einfach zu widerlegen. Es ist daher etwas ärgerlich, dass sich solche Gerüchte überhaupt so hartnäckig halten. Dass die neuen mRNA-Impfungen unser Genom verändern könnten, gehört also eindeutig in die Gruppe hanebüchener Impfmythen.